Recently a customer had a few issues with having all VMs using the same path to the LUNs, this was down to putting too many workloads onto servers that were used as a proof of concept. Inadvertently, SAN problems arose so I was asked to checkover the storage.
First a little background on the infrastructure.... a number of rack servers plus a number of blade servers, hooked into two fabrics with IBM SVC as the backend. Each ESX server has two FC HBA, and each fabric switch had two connections to the SVC, therefore each ESX server has four possible paths to the LUNs. The paths were all active as shown on this pic:
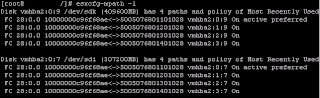
As you can see the path policy is currently set to mru, most recently used path policy is best used in an active/passive configuration.
mru:
- LUNs presented on single Storage Processor at any one time
- Failover on NOT_READY, ILLEGAL_REQUEST or NO_CONNECT
- No preferred path policy
- No failback to preferred path if it returns online after failover
Since, esxcfg-mpath -l shows that we are in fact using active/active, it is best to change the policy to fixed path policy:
- LUNs presented on multiple Storage Processors at same time
- Failover over on NO_CONNECT
- Preferred path policy
- Failback to preferred path if it returns online after failover
So how do we now go about changing the policies on all our servers? Well we could use VI-Client and change each datastore to use a different path - doing this for 10 datastores per server with 20+ servers? howabout no! The alternative then would be to script it.
The script from
Yellow Bricks is of particular use, as for each LUN it finds it uses a different path for each LUN. The script just sets each LUN up to use a preferred path, but obviously for default installations of ESX, you cannot use preferred path when you are using mru policy. So we must change all LUNs to use fixed path policy first.
By re-using the script form Yellow Bricks, I've come up with this:
# vmhbafixedpath.sh Script to rescan vmhbas on ESX 3.5 host
# Written by hugo@vmwire.com
# 21/05/2008 18:20
for PATHS in 2 4 6 8
do
STPATHS=${PATHS}
COUNTER="1"
for LUN in $(esxcfg-mpath -l | grep "has ${STPATHS} paths" | awk '{print $2}')
do
esxcfg-mpath --lun=${LUN} -p fixed
COUNT=`expr ${COUNTER} + 1`
COUNTER=${COUNT}
if [[ ${COUNTER} -gt ${STPATHS} ]]
then
COUNTER="1"
fi
done
done
Then use the script from Yellow Bricks, to set up the preferred paths. Now the changes do not take into effect until the HBAs are rescanned, and the Storage is refreshed. The following script rescans the HBAs
#!/bin/bash
# rescanhbas.sh Script to rescan vmhbas on ESX 3.5 host
# Written by hugo@vmwire.com & nkouts
# 21/05/2008 18:50
# Assumes there is no vmhba0 and max vmhba9
for HBAS in 2 4
do
STHBAS=${HBAS}
COUNTER="1"
for HBA in $(esxcfg-info -w | grep vmhba | awk '{print $3}' | grep -e 'vmhba\+[1-9]' -o)
do
esxcfg-rescan ${HBA}
COUNT=`expr ${COUNTER} + 1`
COUNTER=${COUNT}
if [[ ${COUNTER} -gt ${STHBAS} ]]
then
COUNTER="1"
fi
done
done
And there is no known console based method to refresh the storage subsystem (anyone?) apart from using VI-Client, rebooting the ESX host or restarting the vmware management service:

service mgmt-vmware restart
 UPDATE: Use /usr/bin/vmware-vim-cmd to refresh the storage
UPDATE: Use /usr/bin/vmware-vim-cmd to refresh the storage
/usr/bin/vmware-vim-cmd hostsvc/storage/refresh
So now we have the servers using different paths for each datastore.
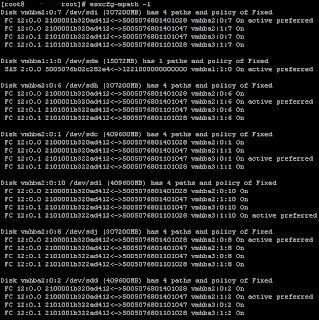
It only took a couple of seconds to change the policies on each server using these scripts, obviously using these as part of a build script would be ideal for deployments where you know the SAN configuration.



 this shows that vmhba2 is currently active and has 4-paths to the SAN
this shows that vmhba2 is currently active and has 4-paths to the SAN
 The -q option shows configured options for a module.
The -q option shows configured options for a module.




